Интернет – то место, где можно отыскать все, что угодно. То, что однажды попало в Сеть, будет сохраняться там вечно, нужно лишь уметь «достать» информацию – а это абсолютно реально сделать даже в том случае, если сайт лежит или давным-давно перестал работать, то есть – просто так не откроется. Получить доступ в таком случае помогут стандартные возможности браузера, особая команда либо специальные веб-сайты.
Способ № 1
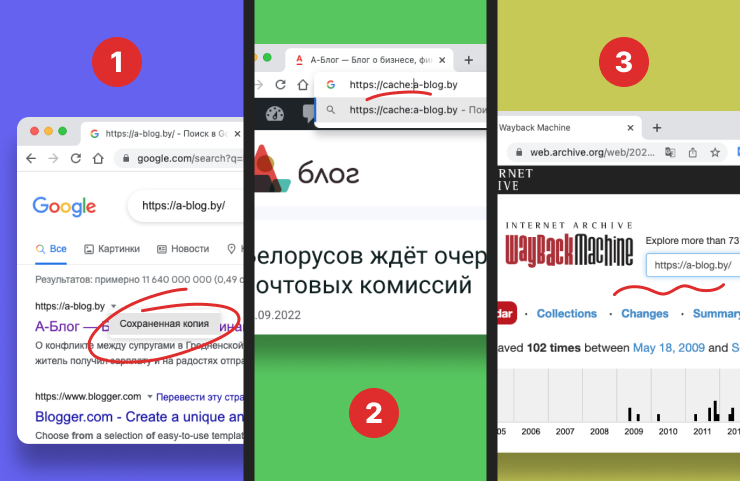
Функция, о которой пойдет речь ниже, доступна пользователям практически во всех популярных поисковых системах, но рассмотрим мы эту фишку на примере поисковика Google, в котором резервные копии веб-страниц сохраняются на его серверах в кэше. Сделано это специально для того, чтобы с ними можно было поработать, когда веб-сайт по какой-то причине станет сам по себе недоступен. Чтобы попасть на лежащий сайт, нужно сделать следующее:
- Ввести в поисковой строке Google название сайта и запустить поиск.
- В результатах поиска справа от найденной ссылки (название сайта и/или его URL) нажать маленькую серую стрелочку – выпадет краткое меню (как правило, всего из двух строк).
- Выбрать строку «Сохраненная копия» и перейти на искомый сайт – сохраненную его версию, которой можно пользоваться практически так же полноценно, как и самим сайтом.
Кстати, воспользоваться данной функцией можно еще в двух случаях – если нужные страницы грузятся чересчур медленно либо не загружаются вообще.
Способ № 2
В строку браузера вписать адрес страницы, затем встать на его начало (установить курсор слева) и ввести команду «cache:» (без кавычек, слово вводится с двоеточием после него). Пример: cache:google.ru (откроется кэшированная версия).
Способ № 3
Очень старые сайты можно открыть через два веб-ресурса, старающихся архивировать всю Мировую Сеть:
- Wayback Machine – отыщутся веб-сайты, аудио, видео, тексты, изображения и приложения, созданные по 15 декабря 1996 года. URL нужной веб-страницы ввести в строку поиска и нажать кнопку BROWSE HISTORY справа от строки.
- Archive.Today – пользоваться можно аналогично вышеуказанному архиву, информация имеется по 2011 год. Также предоставляется возможность самостоятельно архивировать нужные страницы (к примеру – свой блог, свои посты в каком-либо форуме и т.п.).
Альтернативный вариант трем вышеприведенным способам – использовать расширения: для браузера Google Chrome – Web Cache Viewer, для Google Chrome и Firefox – Web Archives.
Читайте также: